on
AWS Glue and S3A committers

I recently worked on an AWS Glue job written in Python. AWS Glue being a managed service on top of Apache Spark framework.
Each day this job has to process few hundred of GBs of data located in S3. It is doing grouping and aggregations and then writing transformed data back to S3 in Parquet format.
I have configured job to run on a good amount of workers. And data partitioning was ensured before joins and groupBy operations to avoid common performance issues in Spark.
Then I launched it for the first time on a real dataset and it appeared to take a lot of time especially when it was writing transformed data to S3.
The problem
During writing of transformed data in S3 destination there was a special directory alongside partitions: .spark-staging-206f5724-c84f-4a53-804a-6a4dfc238800/. This directory is temporary and contains newly written data.
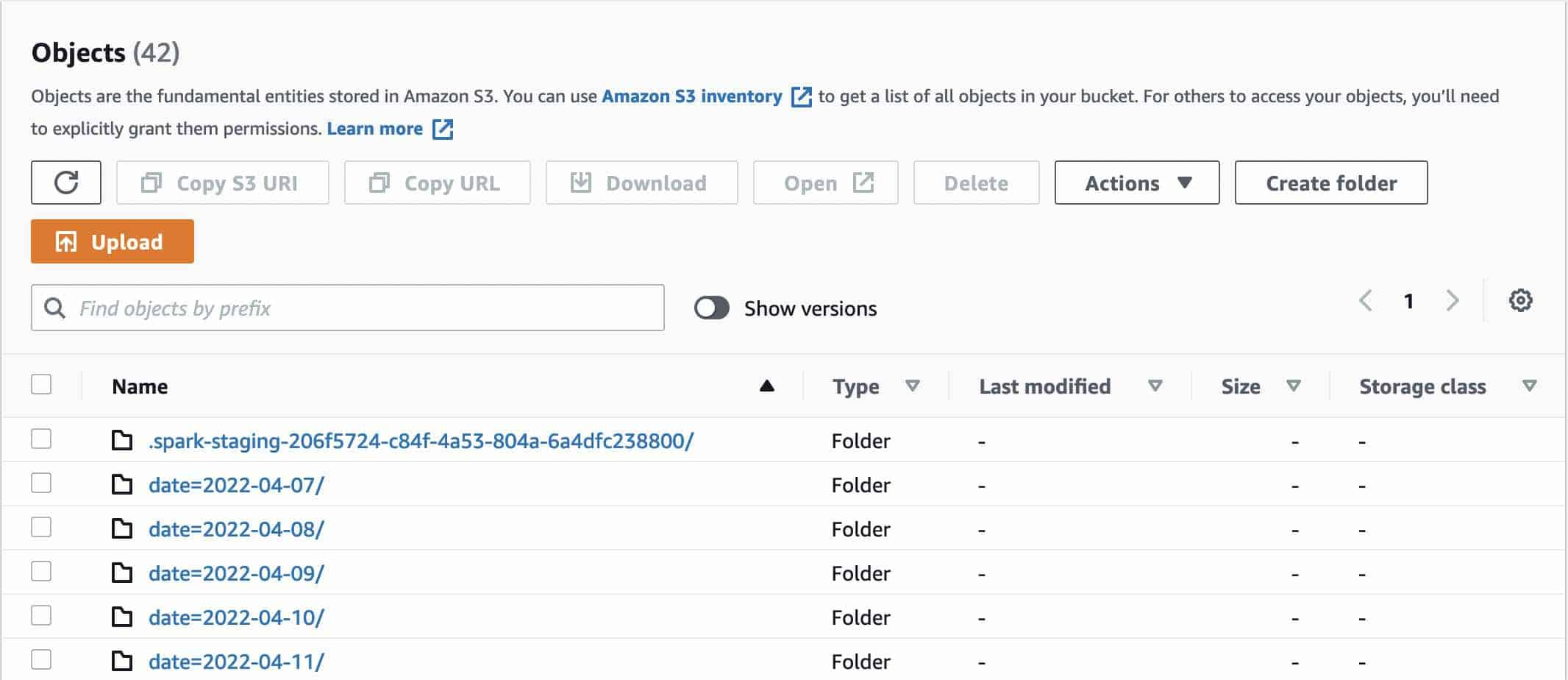
This is how FileOutputCommitter of Hadoop works, Spark use it by default when writing data. It writes data in this staging directory and then move each file into its final partition destination.
Move operation is fast and O(1) complexity on a regular filesystem like Hadoop Distributed File System (HDFS). But on an object store like S3 it is more expensive as it includes more operations:
- Check if destination already exists and delete it
- Copy content of source file to destination
- Delete source file
During this process, concurrent reads on the dataset are inconsistent as rename is not an atomic operation on S3.
Hadoop tackled this problem in version 3.1 and introduced specific committers for S3 compatible object stores, the S3A Committers. You can find technical details and differences between them on this page: Committing work to S3 with the “S3A Committers”.
Important thing to know is that these committers don’t rely anymore on a staging directory and move mechanism but on S3 Multipart Upload mechanism. In each Spark task files are progressively assembled in a pending Multiplart upload which is then marked completed when task succeeds.
My goal was to try to use one of those S3A committer in my Glue job.
Glue EMRFS S3-optimized committer
Glue 3 announced support for Amazon S3 optimized output committers. It turned out that new parameter introduced –enable-s3-parquet-optimized-committer was enabling usage of EMRFS S3-optimized committer which is AWS own implementation of S3 committer and not one of S3A committer of Hadoop.
This EMRFS S3-optimized seems nice but it doesn’t work when we want to overwrite data at partition level (i.e parameter spark.sql.sources.partitionOverwriteMode is set to dynamic in spark config) which was behavior I wanted in my Glue job.
Setup S3A Committers in AWS Glue 3
Setup is not straightforward and took me some time to understand and validate everything. I will describe the procedure step by step:
1) Add spark-hadoop-cloud module
First you need to download spark-hadoop-cloud JAR available on Maven Central: spark-hadoop-cloud-3.2.1.
You have to upload it somewhere on a S3 bucket and add it in --extra-jars parameter of your Glue job:
--extra-jars s3://my-bucket/path/to/spark-hadoop-cloud_2.12-3.2.1.jar
Versions 2.12 and 3.2.1 being respectively versions of Scala and Hadoop used on AWS Glue 3.
This JAR contains classes that will allow usage of S3A committer when writing data into S3 through Spark APIs.
2) Configure Spark
In your Glue job code, you have to declare SparkConf with some configurations shown as below:
from awsglue.context import GlueContext
from pyspark.context import SparkContext
from pyspark import SparkConf
sconf = SparkConf()
sconf.set(
"spark.sql.sources.commitProtocolClass",
"org.apache.spark.internal.io.cloud.PathOutputCommitProtocol"
)
sconf.set(
"spark.sql.parquet.output.committer.class",
"org.apache.spark.internal.io.cloud.BindingParquetOutputCommitter"
)
# register hadoop s3a filesystem
sconf.set("spark.hadoop.fs.s3.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem")
sconf.set("spark.hadoop.fs.defaultFS", "s3a://my-bucket")
# refer to https://hadoop.apache.org/docs/r3.1.1/hadoop-aws/tools/hadoop-aws/committers.html
# for which committer and which conflict mode you want to chose
sconf.set("spark.hadoop.fs.s3a.committer.name", "partitioned")
sconf.set("spark.hadoop.fs.s3a.committer.staging.conflict-mode", "replace")
sc = SparkContext.getOrCreate(conf=sconf)
glueContext = GlueContext(sc)
spark = glueContext.spark_session
PathOutputCommitProtocol and BindingParquetOutputCommitter are classes located in spark-hadoop-cloud JAR and are set as default commitProtocolClass and committer in Spark.
Then we configure which S3A committer we want to use. In my case I use partitioned committer because it resolves data overwriting at partition level with configuration fs.s3a.committer.staging.conflict-mode set to replace.
I define s3a://my-bucket as Hadoop defaultFS. It is because some committers like partitioned one need a filesystem accessible across the cluster to share pending commits. Since Glue does not include HDFS, I set it to a S3 bucket with S3A protocol.
Note that I removed spark.sql.sources.partitionOverwriteMode => dynamic config. I will save my dataframe with append mode instead of overwrite and this will delegate partition conflict resolution to S3A committer.
3) Verify
We use Spark SQL API to write data into S3:
mydataframe = spark.createDataFrame(...)
mydataframe.write.mode("append").parquet("s3a://my-bucket/data.parquet")
And analyze output logs of job run in Cloudwatch:
2022-05-25 10:40:13,528 INFO [Thread-10] commit.AbstractS3ACommitterFactory (S3ACommitterFactory.java:createTaskCommitter(83)): Using committer partitioned to output data to s3a://my-bucket/data.parquet
2022-05-25 10:40:13,529 INFO [Thread-10] commit.AbstractS3ACommitterFactory (AbstractS3ACommitterFactory.java:createOutputCommitter(54)): Using Commmitter PartitionedStagingCommitter{StagingCommitter{AbstractS3ACommitter{role=Task committer attempt_202206031040131882231241413757290_0000_m_000000_0, name=partitioned, outputPath=s3a://my-bucket/data.parquet, workPath....
If you see these logs, congratulations you are using S3A committer in your Glue job!
You can also verify inside S3 bucket you configured as spark.hadoop.fs.defaultFS that there is a directory user/spark/tmp/staging/spark/ created. This is the directory used when job is running to store pending commits between Spark tasks. These files are written using classic FileOutputCommitter but this is not a problem here as it just contains commits informations (few Kilobytes) and not actual data.
Performances
With S3A partitionned committer setup, duration of my Glue job went from 50 minutes to 20 minutes. I tried to apply this configuration on other existing Glue jobs and I also noticed between 40 and 60% time improvements. If your job write a lot of data or partitions S3A committers will definitely reduce writing duration compared to the classic FileOutputCommitter.
Further Notes
As you see configuration is not straightforward as we have to deal with both Spark and Hadoop configurations + include an extra JAR in Glue job. I hope that in future {Spark/Hadoop/Glue} versions setup and configuration will be easier.
New table formats like Delta Lake or Iceberg were developed and they aim to solve these type of issues when working with cloud data lakes. I have written in more detail about Iceberg.
heading image source: ninocare at https://pixabay.com